
Making Flammable Pants
tl;dr version I built a site that collects fact checks from 6 news/fact checking organizations. If — like me — you wanted a single place… Read More »Making Flammable Pants
tl;dr version I built a site that collects fact checks from 6 news/fact checking organizations. If — like me — you wanted a single place… Read More »Making Flammable Pants

UPDATE 2: August 8, 5:00 AM Pacific On August 7, Zoom updated their terms to include a line that specifies that Zoom will only use… Read More »Zoom, Mining Content for Fun and ??

Gas is the latest app to get attention from the hand-waving wing of the edtech press. In general, I try and ignore coverage of “the… Read More »Out of Gas

slackuum. Noun. ‘slak-kyüm The verbose blend of attempted productivity and despair that occurs when a company deploys Slack as an email replacement without defining if… Read More »Slackuum

Not that it matters, but I’m dialing back/entirely eliminating my use of Twitter. Life is too short, and I’ll be spending my time in nice… Read More »Going Someplace Nice
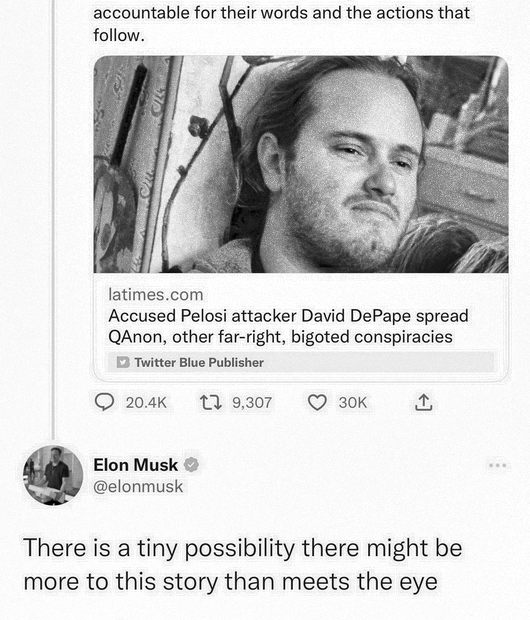
Many people have written many things about Elon Musk’s bank-funded, Saudi-supported, Jack Dorsey-supported, Binance-supported acquisition of Twitter, to the point where I seriously question my… Read More »Twitter Is Now the Go-To Place for Source Hacking – and the Owner is the Source

It’s human nature to try and reduce things down to a binary – a yes/no, either/or – but reality tends to be more both/and with… Read More »Reducing Risk Is Not the Same as Remote Learning
tl;dr I’ve been working on extracting text from the released pdfs of the Facebook Papers. The cleaned pdfs, the extracted text and the code used… Read More »Making Text from the Facebook Papers More Accessible
Keeping even a simple web site up to date is work, and anything we can do to reduce the time required is a good thing.… Read More »FunnyMonkey gets a technical facelift